自習用コンテンツ その6(https://automate.sct.co.jp/knowledge/12053/)の内容は如何でしたでしょうか?
簡単に出来てしまった方も、難しかった方もいたかと思います。
下記では、解説を書いていきます。
(解答例のコードは、ページ最下部に書いています。)
■観点
今回のコンテンツでは、PDFファイルのページ分割、テキスト抽出、および特定文字列の抽出を観点としました。
文字をコピー&ペースト出来るPDFの場合、テキストの抜き出しが可能なため、OCRなどの外部ツールが必要ありません。
※文字選択のできないただの画像の場合は対応できません。
■1. 必要な変数の用意
今回の処理では、以下の2つの変数が必要になります。
・PDFファイルから抽出したテキストの格納先となる変数
・管理番号を格納する変数
なお、「管理番号」を格納する変数ですが、「0」が消えてはならないという制約があります。
仮に「数値」と判断された場合、先頭の「0」が消えてしまいます。そのため、今回は明示的に変数の型を「Text」で宣言します。
<AMVARIABLE NAME="var_text" DESCRIPTION="PDFファイルから抽出したテキストの格納先" VALUE="" />
<AMVARIABLE NAME="var_kanriNo" DESCRIPTION="管理番号の格納先 先頭の「0」が消えてはならないので、文字列型で宣言" TYPE="text" VALUE="" />
■2. PDFファイルをページごとに分割する
PDFファイルをページごとに分割するには、「PDF - 分割」アクションを使用します。
こちらを使用すると、外部のツールを使用することなく、PDFファイルの分割が可能となります。
(図1: PDF - 分割)
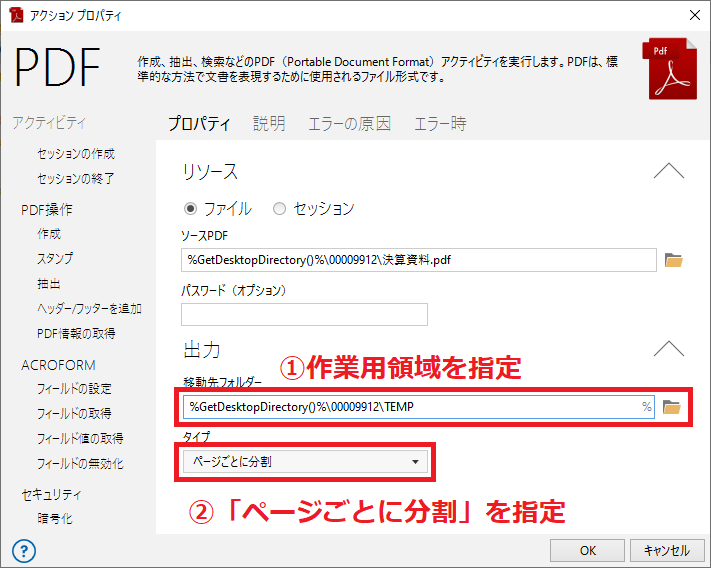
図1の①の項目には、作業用領域を指定します。また、ここでは作業用領域は空のフォルダであることを想定します。
(もとになるPDFと同じ場所を指定すると、次以降のステップでそのPDFファイルをIF条件で除外する等、条件が複雑になります)
<AMPDF ACTIVITY="split" SOURCE="%GetDesktopDirectory()%\00009912\00009912.pdf" SPLITFOLDER="%GetDesktopDirectory()%\00009912\TEMP" SPLIT="page" />
■3. 処理対象のPDFファイル一覧をデータセットとして取得する
分割したPDFファイルの一覧を取得するため、「ファイル システム - 情報の取得」アクションを使用します。
■2で分割したファイルの出力先フォルダを情報取得対象に指定します。ここでは、データセット名を「ds_pdf」とします。
<AMFILESYSTEM ACTIVITY="get" SOURCE="%GetDesktopDirectory()%\00009912\TEMP\*.pdf" RESULTDATASET="ds_pdf" FILEPROPERTY="fullname" />
■4. ■3のデータセットに従い、ループ
取得したPDFファイルのリストを一つずつ処理するため、「Loop - データセット」を使用して繰り返し処理を行います。
<AMLOOP ACTIVITY="dataset" DATASET="ds_pdf" />
-----------------------------------以下、ループ内処理-----------------------------------
■5. PDFの内容をテキストとして抽出する
今回のPDFは、文字をコピーできるタイプのPDFのため、内容のテキストを抽出することが出来ます。
「PDF - 抽出」アクションを使用し、PDFの内容のテキストを変数化します。
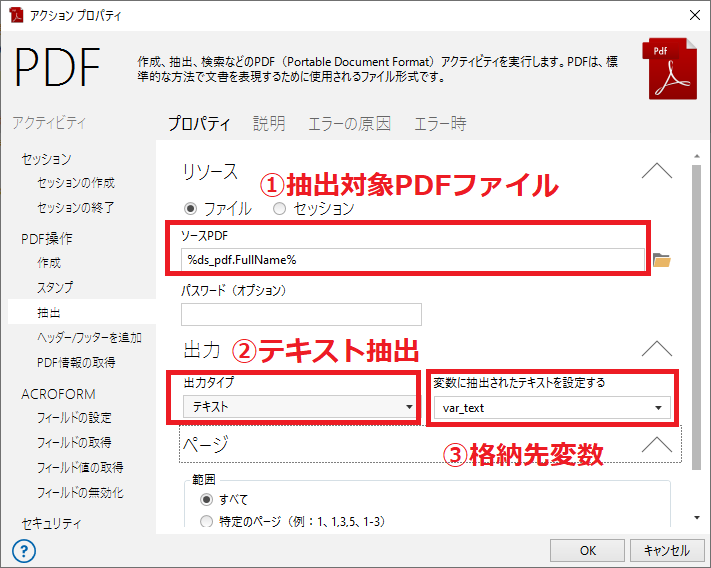
①には現在ループにて処理中の行におけるPDFのフルパス「%ds_pdf.Fullname%」を指定します。
<AMPDF SOURCE="%ds_pdf.FullName%" RESULTVARIABLE="var_text" />
■6. 抽出したテキストから管理番号を抜き出す
■5の結果、以下のようなテキストが変数に抽出されます。(下記は、AutoMateのコードではなく、ただの平文なのでご注意ください)
管理番号:0002735
商品名 売上高 前年比
りんご 3000 +10%
バナナ 40000 +20%
このファイルはテストデータです。
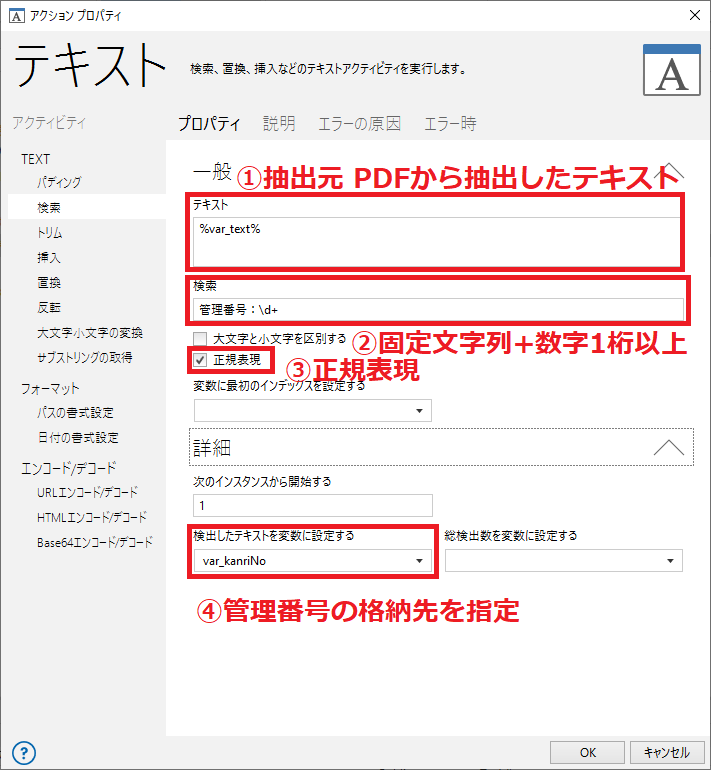
上記のテキストから、管理番号に関する部分を抽出します。
管理番号は必ず「管理番号:」の固定文字列 + 半角数字 の並びとなっています。
そのため、「テキスト - 検索」アクションと正規表現を併用することで取得できます。
(図3. テキスト - 検索)
<AMTEXT TEXT="%var_text%" FIND="管理番号:\d+" USERE="YES" FOUNDTEXTVARIABLE="var_kanriNo" />
■7. 抽出した管理番号を数字のみにする
■6で抽出した状態では、数字の前に固定文字列「管理番号:」がついています。
これを取り除くため、「テキスト - 置換」アクションでNothingに置き換えます。
<AMTEXT ACTIVITY="replace" TEXT="%var_kanriNo%" FIND="管理番号:" REPLACE="" RESULTVARIABLE="var_kanriNo" />
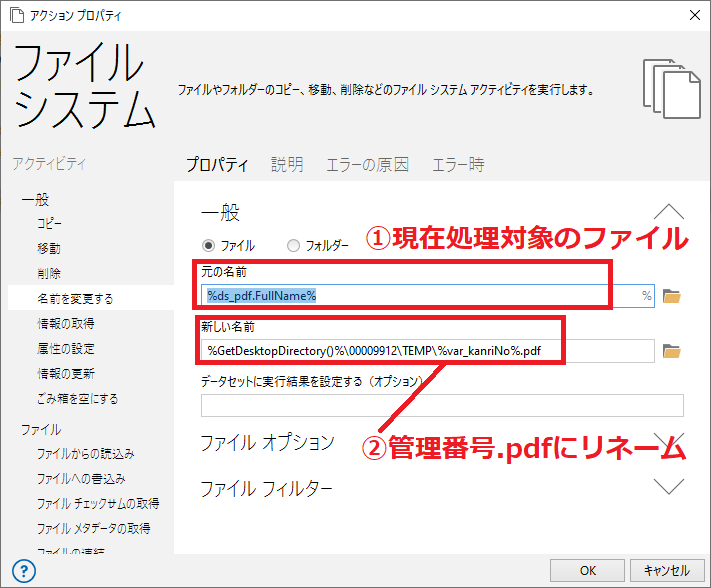
■8. PDFファイルをリネームする
「ファイルシステム - 名前を変更する」アクションを使用し、分割したファイルを「<管理番号>.pdf」にリネームします。
<AMFILESYSTEM ACTIVITY="rename" SOURCE="%ds_pdf.FullName%" DEST="%GetDesktopDirectory()%\00009912\TEMP\%var_kanriNo%.pdf" />
-----------------------------------以上、ループ内処理-----------------------------------
■9. ループの終わり
ファイルをリネームするまでが一連の繰り返し処理なので、リネームするステップがループの終わりになります。
<AMLOOP ACTIVITY="end" />
今回定義する処理は以上になります。
(処理構築例:展開するにはここをクリック)
<!--変数宣言-->
<AMVARIABLE NAME="var_text" DESCRIPTION="PDFファイルから抽出したテキストの格納先" VALUE="" />
<AMVARIABLE NAME="var_kanriNo" DESCRIPTION="管理番号の格納先 先頭の「0」が消えてはならないので、文字列型で宣言" TYPE="text" VALUE="" />
<!--PDF分割-->
<AMPDF ACTIVITY="split" SOURCE="%GetDesktopDirectory()%\00009912\00009912.pdf" SPLITFOLDER="%GetDesktopDirectory()%\00009912\TEMP" SPLIT="page" />
<!--分割したPDFをデータセット化-->
<AMFILESYSTEM ACTIVITY="get" SOURCE="%GetDesktopDirectory()%\00009912\TEMP\*.pdf" RESULTDATASET="ds_pdf" FILEPROPERTY="fullname" />
<AMLOOP ACTIVITY="dataset" DATASET="ds_pdf" />
<!--PDF内のテキストを変数に抽出-->
<AMPDF SOURCE="%ds_pdf.FullName%" RESULTVARIABLE="var_text" />
<!--固定文字列「管理番号:」+数字の文字列を探す-->
<AMTEXT TEXT="%var_text%" FIND="管理番号:\d+" USERE="YES" FOUNDTEXTVARIABLE="var_kanriNo" />
<!--数字以外を除去-->
<AMTEXT ACTIVITY="replace" TEXT="%var_kanriNo%" FIND="管理番号:" REPLACE="" RESULTVARIABLE="var_kanriNo" />
<!--ファイルをリネーム-->
<AMFILESYSTEM ACTIVITY="rename" SOURCE="%ds_pdf.FullName%" DEST="%GetDesktopDirectory()%\00009912\TEMP\%var_kanriNo%.pdf" />
<AMLOOP ACTIVITY="end" />